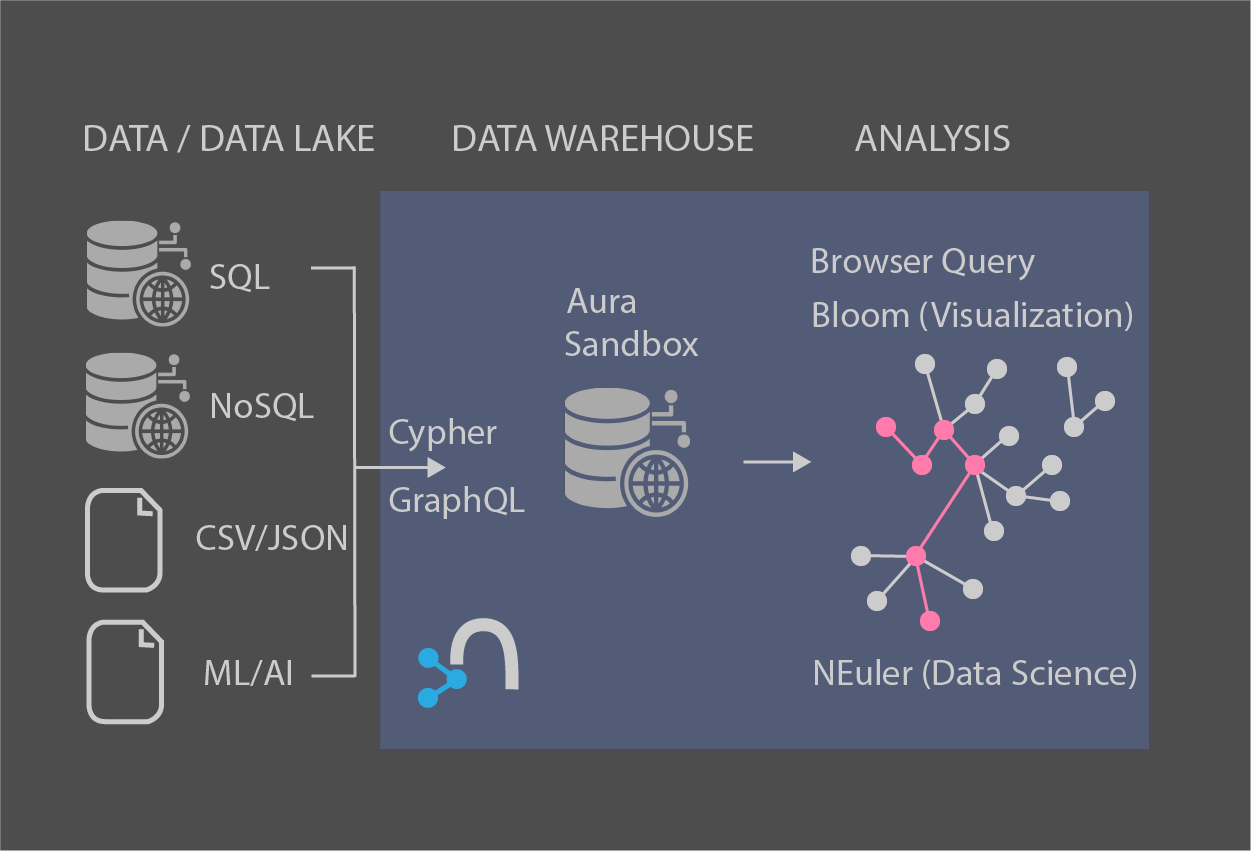
<p>This is mainly referenced from<a href="https://neo4j.com/docs/graph-data-science/current/" target="_blank"> Neo4j Graph Data Science Document.</a></p><p><br></p><ol><li><span style="font-size: 18px;">Centrality Algorithms</span></li><li><span style="font-size: 18px;">Community Detection Algorithms</span></li><li><span style="font-size: 18px;">Similarity Algorithms</span></li><li><span style="font-size: 18px;">Path Finding Algorithms</span></li><li><span style="font-size: 18px;">Link Prediction Algorithms</span></li><li><span style="font-size: 18px;">Node Embeddings</span></li></ol><p><br></p><h2>1. Centrality Algorithms</h2><blockquote><p>Centrality algorithms are used to determine the importance of distinct nodes in a network</p></blockquote><p>Followings are popular algorithms under centrality algorithms;</p><ul><li><span style="font-size: 12px;"><span style="font-size: 14px;">P</span><span style="font-size: 14px;">age Rank</span></span></li><li><span style="font-size: 14px;">Betweenness Centrality</span></li><li><span style="font-size: 14px;">Article Rank</span></li><li><span style="font-size: 14px;">Eigenvector Centrality</span></li><li><span style="font-size: 14px;">Degree Centrality</span></li></ul><p><br></p><h3>Page Rank</h3><blockquote>The PageRank algorithm measures the importance of each node within the graph, based on the number incoming relationships and the importance of the corresponding source nodes. The underlying assumption is that a page is only as important as the pages that link to it.</blockquote><p><br></p><h3 style="font-family: "Helvetica Neue", Helvetica, Arial, sans-serif; color: rgb(0, 0, 0);">Betweenness Centrality</h3><blockquote><p>Betweenness Centrality is a way of detecting the amount of influence a node has over the flow of information in a graph. It is often used to find nodes that serve as a bridge from one part of a graph to another<br>The algorithm calculates unweighted shortest paths between all pairs of nodes in a graph. Each node receives a score, based on the number of shortest paths that pass through the node. Nodes that more frequently lie on shortest paths between other nodes will have higher betweenness centrality scores</p></blockquote><p>This is somewhat similar to `page rank` algorithm to quantify the magnitude of influence, but it is not identical. </p><blockquote><p>In general Betweenness Centrality is a good metric to identify bottlenecks and bridges in a graph while Page Rank is used to understand the influence of a node in a network</p></blockquote><p><br></p><p><br></p><h2 style="font-family: "Helvetica Neue", Helvetica, Arial, sans-serif; color: rgb(0, 0, 0);">2. Community Detection Algorithms</h2><blockquote>Community detection algorithms are used to evaluate how groups of nodes are clustered or partitioned, as well as their tendency to strengthen or break apart</blockquote><p>Followings are popular community detection algorithms;</p><ul><li>Louvain</li><li>Triangle Count</li><li>Local Clustering Coefficient</li><li>Label Propagation (LPA)</li><li>Weakly Connected Components </li></ul><p><br></p><h3>Louvain</h3><blockquote>The Louvain method is an algorithm to detect communities in large networks. It maximizes a modularity score for each community, where the modularity quantifies the quality of an assignment of nodes to communities. This means evaluating how much more densely connected the nodes within a community are, compared to how connected they would be in a random network.<br>The Louvain algorithm is a hierarchical clustering algorithm, that recursively merges communities into a single node and executes the modularity clustering on the condensed graphs.</blockquote><p><br></p><h3>Triangle Count</h3><blockquote>The Triangle Count algorithm counts the number of triangles for each node in the graph. A triangle is a set of three nodes where each node has a relationship to the other two.<br>Triangle counting has gained popularity in social network analysis, where it is used to detect communities and measure the cohesiveness of those communities. It can also be used to determine the stability of a graph, and is often used as part of the computation of network indices, such as clustering coefficients.</blockquote><p><br></p><h3 style="font-family: "Helvetica Neue", Helvetica, Arial, sans-serif; color: rgb(0, 0, 0);">Local Clustering Coefficient</h3><blockquote><p>The local clustering coefficient is a metric quantifying how connected the neighborhood of a node is. It is the probability that two random neighbors of the node are connected in the graph. This can be obtained from the triangle count and the degree of the node. The Graph Data Science library provides procedures for all standard execution modes in the namespace `gds.localClusteringCoefficient`. The algorithm is only defined for undirected graphs, so we make sure to fulfill this requirement.<br></p></blockquote><p><br></p><h3>Label Propagation (LPA)</h3><blockquote>The Label Propagation algorithm (LPA) is a fast algorithm for finding communities in a graph. It detects these communities using network structure alone as its guide, and doesn't require a pre-defined objective function or prior information about the communities.<br>LPA works by propagating labels throughout the network and forming communities based on this process of label propagation.<br>The intuition behind the algorithms is that a single label can quickly become dominant in a densely connected group of nodes, but will have trouble crossing a sparsely connected region. Labels will get trapped inside a densely connected group of nodes, and those nodes that end up with the same label when the algorithms finish can be considered part of the same community.</blockquote><p><br></p><h3>Weakly Connected Components (WCC)</h3><blockquote>The WCC algorithm finds sets of connected nodes in an undirected graph, where all nodes in the same set form a connected component. WCC is often used early in an analysis to understand the structure of a graph.<br>Using WCC to understand the graph structure enables running other algorithms independently on an identified cluster. As a preprocessing step for directed graphs, it helps quickly identify disconnected groups.</blockquote><p><br></p><h2>3. Similarity Algorithms</h2><blockquote><p>Similarity algorithms compute the similarity of pairs of nodes using different vector-based metrics.</p></blockquote><p>Followings are popular algorithms under similarity algorithms</p><ul><li>Node Similarity</li><li>K-Nearest Neighbors</li><li>Cosines Similarity</li><li>Euclidean Similarity</li><li>Jaccard Similarity</li></ul><p><br></p><h3>Node Similarity</h3><blockquote>The Node Similarity algorithm compares a set of nodes based on the nodes they are connected to. Two nodes are considered similar if they share many of the same neighbors. Node Similarity computes pair-wise similarities based on the Jaccard metric, also knows as the Jaccard Similarity Score.</blockquote><p><br></p><h3>Jaccard Similarity</h3><blockquote>Jaccard Similarity (coefficient) measures similarities between sets. It is defined as the size of the intersection divided by the size of the union of two sets. This notion has been generalized for multisets, where duplicate elements are counted as weights.</blockquote><p><br></p><h2>4. Path Finding Algorithms</h2><blockquote>Path finding algorithms find the shortest path between two or more nodes or evaluate the availability and quality of paths.</blockquote><p>Followings are path finding algorithms;</p><ul><li>Dijkstra Source-Target</li><li>Dijkstra Single-Source</li><li>A* (A Star)</li></ul><p><br></p><h2>5. Link Prediction</h2><blockquote>Link prediction is a common machine learning task applied to graphs: training a model to learn, between pairs of nodes in a graph, where relationships should exist. Algorithms help determine the closeness of a pair of nodes. The computed scores can then be used to predict new relationships between them, so you can think of this as building a model to predict missing relationships in your dataset or relationships that are likely to form in the future.</blockquote><p>Followings are link prediction algorithms;</p><ul><li>Adamic Adar</li><li>Common Neighbors</li></ul><p><br></p><h2>6. Node Embeddings</h2><blockquote><p>Node embedding algorithms compute low-dimensional vector representations of nodes in a graph. These vectors, also called embeddings, can be used for machine learning for Node Classification</p></blockquote><h3>Node Classification</h3><blockquote>Node Classification is a common machine learning task applied to graphs: training a model to learn in which class a node belongs. The algorithm trains supervised machine learning models based on node properties(features) in your graph to predict what class an unseen or future node would belong to. Node classification can be used favorably together with pre-processing algorithms.<br>Concretely, Node classification models are used to predict a non-existing node property based on other node properties. The non-existing node property represents the class, and is referred to as the target property. The specified node properties are used as input features. The Node Classification model does not rely on relationship information. However, a node embedding algorithm <b>could embed the neighborhoods of nodes as a node property</b>, to transfer this information into the Node Classification model.</blockquote><p><br></p><p>Machine learning algorithm that is based on the embeddings are followings;</p><ul><li>FastRP (Fast Random Projection)</li><li>GraphSAGE</li><li>Node2Vec</li></ul><p><br></p><p>Below simply summarizes use cases for each from Neo4j</p><p><img src="/media/django-summernote/2021-07-05/23fff273-4f01-4abe-bb8d-227427f631db.png" style="width: 100%;"><br></p><p><br></p><h3>GraphSAGE</h3><blockquote>GraphSAGE is an inductive algorithm for computing node embeddings. GraphSAGE is using node feature information to generate node embeddings on unseen nodes or graphs. Instead of training individual embeddings for each node, the algorithm learns a function that generates embeddings by sampling and aggregating features from a node's local neighborhood</blockquote>
<< Back to Blog Posts
Back to Home