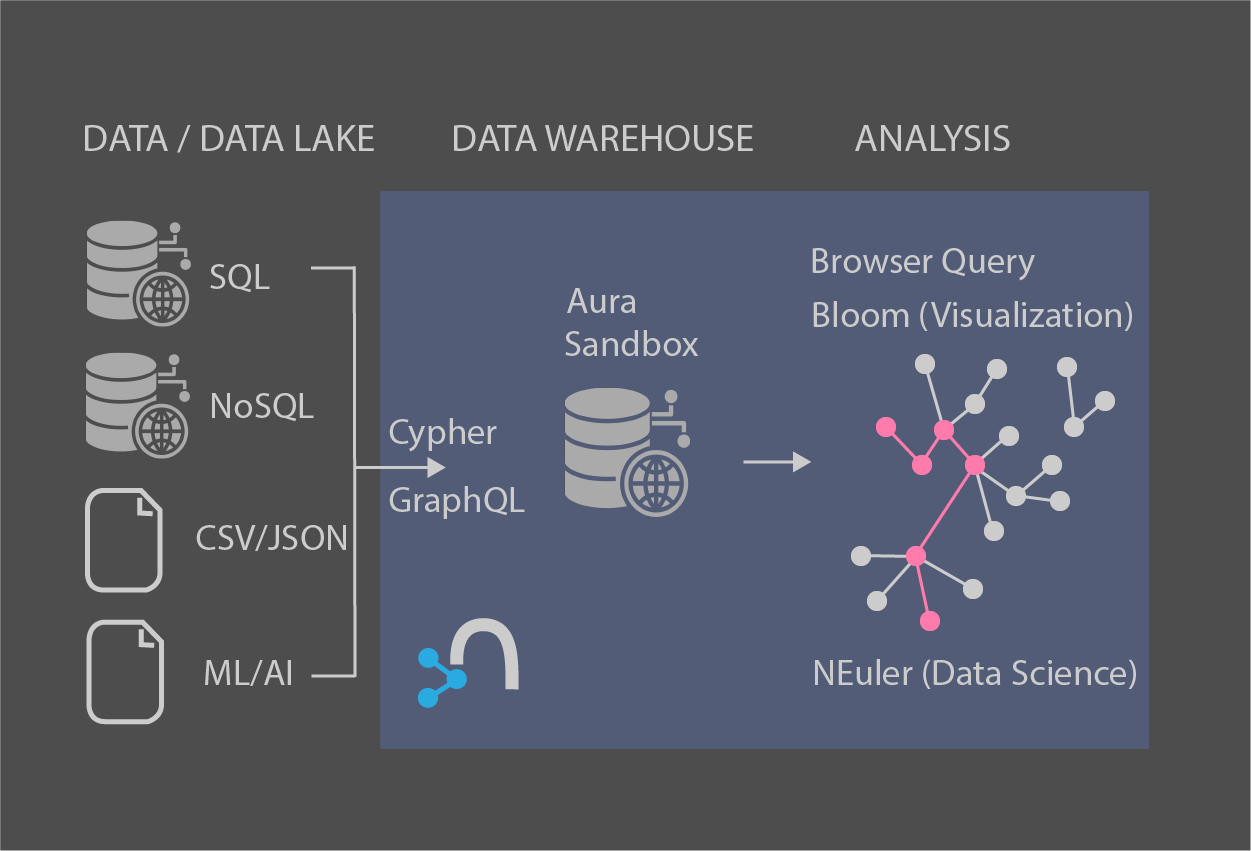
<p>This is mainly referenced by <a href="https://neo4j.com/docs/graph-data-science/current/introduction/" target="_blank">neo4j graph data science documents</a></p><p><br></p><ol><li>Graph data set and Exploratory Data Analysis</li><li>Memory Management</li><li>Graph Creation</li><li>Run Algorithm<ul><li>Page Rank</li><li>Label Propagation</li><li>Weakly Connected Components</li><li>Louvain</li><li>Node Similarity</li><li>Triangle Count</li><li>Local Clustering Coefficient</li></ul></li></ol><p><br></p><h2>1. Graph Data Preparation and Exploratory Data Analysis</h2><p>We will use built-in data from `Game of Thrones` fantasy saga.</p><pre>// Cypher //Load graph data base tutorial with game of thrones datasets :play <a href="https://guides.neo4j.com/sandbox/graph-data-science/index.html" target="_blank">https://guides.neo4j.com/sandbox/graph-data-science/index.html</a></pre><p><br></p><p>Exploratory Data Analysis</p><pre>// Cypher //high level node relationship Call db.schema.visualization() //summary statistics for number of interactions per character MATCH (c:Person)-[:INTERACTS]->() WITH c, count(*) AS num RETURN min(num) AS min, max(num) AS max, avg(num) AS avg_interactinos, stdev(num) AS stdev //summary stats by same grouped by book MATCH (c:Person)-[r:INTERACTS]->() WITH r.book AS book, c, count(*) AS num RETURN book, min(num) AS min, max(num) AS max, avg(num) AS avg_interactions, stdev(num) AS stdev ORDER BY book //high level stats call apoc.meta.stats()</pre><p><br></p><h2>2. Memory Management</h2><p>Assume you have a data and know something about its shape by EDA, you then need to estimate the memory usage of your graph and its algorithms and configure for Neo4j server. This is because;</p><blockquote><p>The graph algorithms run on an in-memory, heap-allocated projection of the Neo4j graph, which resides outside the main database. This means that before you execute an algorithm, you must create a projection of your graph in memory.</p></blockquote><p><br></p><h4>Estimate memory usage for graph creation</h4><pre>// Cypher //to estimate the required memory for a subset of your graph, 'Person' nodes and 'INTERACTS' relationships as an example CALL gds.graph.create.estimate('Person', 'INTERACTS') YIELD nodeCount, relationshipCount, requiredMemory</pre><p><br></p><h4>Create projected graph</h4><pre>// Cypher //create `got-interactions` graph CALL gds.graph.create('got-interactions', 'Person', 'INTERACTS')</pre><p><br></p><h4>Estimate memory usage for algorithm running</h4><pre>// Cypher //estimate the memory needed to execute an algorithm on your `got-interactions` graph, `Page Rank` as an example CALL gds.pageRank.stream.estimate('got-interactions')</pre><p><br></p><h4>Clean up</h4><blockquote><p>If you do not want to use the projected graph anymore, release it from the memory</p></blockquote><pre>// Cypher <p> </p>CALL gds.graph.drop('got-interactions');</pre><p><br></p><h2>3. Graph Creation</h2><blockquote><p>To enable fast caching of the graph topology, containing only the relevant nodes, relationships, and weights, the GDS library operates on in-memory graphs that are created as projections of the Neo4j stored graph.</p></blockquote><p><br></p><h4>Graph Catalog</h4><blockquote><p>The typical workflow is to create the projected graph `explicitly` by giving it a name and storing it in the `graph catalog`. This allows you to operate on the graph multiple times.</p></blockquote><p>You've created graph catalog at section 1 so let's start with removing by ;</p><pre>// Cypher Call gds.graph.drop('got-interactions')</pre><p><br></p><p>Create again, but since each `INTERACTS` relationship is symmetic, you can even ignore its direction by creating your garph with an `UNDIRECTED` orientation.</p><pre>// Cypher Call gds.graph.create('got-interactions', 'Person', { INTERACTS: { orientation: 'UNDIRECTED' } })</pre><p><br></p><h2>4. Run Algorithms</h2><h4>Syntax : explicit graphs</h4><blockquote><p>Running algorithms on explicitly created graphs allows you to operate on a graph multiple times. To do this, refer to the graph by its name, as it is stored in the graph catalog.</p></blockquote><pre>// Cypher CALL gds.<algo-name>.<mode>( graphName: String, configuration: Map )</pre><ul><li><span style="background-color: rgb(255, 255, 255); color: rgb(0, 0, 0); font-family: "Helvetica Neue", Helvetica, Arial, sans-serif; font-size: 14px;"><algo-name> is the algorithm name</span></li><li><span style="background-color: rgb(255, 255, 255); color: rgb(0, 0, 0); font-family: "Helvetica Neue", Helvetica, Arial, sans-serif; font-size: 14px;"><mode> is the algorithm execution mode</span><ul><li><span style="background-color: rgb(255, 255, 255); color: rgb(0, 0, 0); font-family: "Helvetica Neue", Helvetica, Arial, sans-serif; font-size: 14px;">`write` : writes results to the Neo4j database and returns a summary of the results</span></li><li><span style="background-color: rgb(255, 255, 255); color: rgb(0, 0, 0); font-family: "Helvetica Neue", Helvetica, Arial, sans-serif; font-size: 14px;">`stats` : same as `write` but does not write to the Neo4j database</span></li><li><span style="background-color: rgb(255, 255, 255); color: rgb(0, 0, 0); font-family: "Helvetica Neue", Helvetica, Arial, sans-serif; font-size: 14px;">`stream` : streams results back to the user</span></li></ul></li><li><span style="background-color: rgb(255, 255, 255); color: rgb(0, 0, 0); font-family: "Helvetica Neue", Helvetica, Arial, sans-serif; font-size: 14px;">The `graphName` parameter value is the name of the graph from the graph catalog</span></li><li><span style="background-color: rgb(255, 255, 255); color: rgb(0, 0, 0); font-family: "Helvetica Neue", Helvetica, Arial, sans-serif; font-size: 14px;">The `configuration` parameter value is the algorithm-specific configuration</span></li></ul><p></p><p style="line-height: 1.42857;"><br></p><h4 style="line-height: 1.42857;">Page Rank Algorithm</h4><blockquote style="line-height: 1.42857;">Page Rank is an algorithm that measures the transitive influence and connectivity of nodes to find the most influential nodes in a graph.<br>It computes an influence value for each node, called a score. As a results, the score of a node is a certain weighted average of the scores of its direct neighbors.<br>PageRank is an iterative algorithm. In each iteration, every node propagates its score evenly divided to its neighbors.<br>The algorithm runs for a configurable maximum number of iterations (default is 20), or until the node scores converge. That is, when the maximum change in node score between two sequential iterations is smaller than the configured `tolerance` value.</blockquote><pre style="line-height: 1.42857;">// Cypher //Run a basic PageRank call in `stream` mode CALL gds.pageRank.stream('got-interactions') YIELD nodeId, score RETURN gds.util.asNode(nodeId).name AS name, score ORDER BY score DESC LIMIT 10 //compare the Page Rank of each `Person` node with the number of interactions for that node CALL gds.pageRank.stream('got-interactions') YIELD nodeId, score AS pageRank WITH gds.util.asNode(nodeId) AS n, pageRank MATCH (n)-[i:INTERACTS]-() RETURN n.name AS name, pageRank, count(i) AS interactions ORDER BY pageRank DESC LIMIT 10</pre><p style="line-height: 1.42857;">You will see that Page Rank results is not always follows number of interactions.</p><p style="line-height: 1.42857;"><br></p><h4 style="line-height: 1.42857;">Label Propagation</h4><blockquote style="line-height: 1.42857;"><p>Label Propagation (LPA) is a fast algorithm for finding communities in a graph. It propagates labels throughout the graph and forms communities of nodes based on their influence.</p></blockquote><pre>// Cypher // create in-memory graph for LPA run CALL gds.graph.create( 'got-interactions-weighted', 'Person', { INTERACTS: { orientation: 'UNDIRECTED', properties: 'weight' } } ) // run LPA with just on iteration CALL gds.labelPropagation.stream( 'got-interactions-weighted', { relationshipWeightProperty: 'weight', maxIterations: 1 } ) YIELD nodeId, communityId RETURN communityId, count(nodeId) AS size ORDER BY size DESC LIMIT 5 // the algorithm typically needs multiple iterations to achieve a stable result. you would need to repeat to change `maxIterations` multiple time to see when it's converged // clean up graphs from catalog for LPA for next metrics trial CALL gds.graph.drop('got-interactions-weighted');</pre><p><br></p><p><br></p><p><br></p><p><br></p>
<< Back to Blog Posts
Back to Home